HTML-Zeichensätze
HTML-Zeichensätze — ASCII, ANSI, ISO-8859-1 und UTF-8 — und wie man die Kodierung mit dem Meta-charset-Tag korrekt deklariert.
Ein Zeichensatz (oder eine Zeichenkodierung) ist die Zuordnung, die einem Browser mitteilt, wie er die rohen Bytes einer Datei in die Buchstaben, Ziffern, Satzzeichen und Symbole umwandelt, die auf dem Bildschirm erscheinen. Der Browser muss wissen, welchen Zeichensatz eine Seite verwendet, um sie korrekt anzuzeigen.
UTF-8 ist die Standard-Zeichenkodierung für HTML5. Das war nicht immer so. ASCII kam zuerst, und ISO-8859-1 war der Standard-Zeichensatz von HTML 2.0 bis HTML 4.01. Jeder dieser älteren Zeichensätze konnte nur einen begrenzten Bereich von Zeichen darstellen, was bei nicht-englischem Text zu Problemen führte. Als UTF-8 zusammen mit HTML5 und XML eingeführt wurde, löste es die meisten dieser Probleme, indem es nahezu jedes Schriftsystem in einer einzigen Kodierung abdeckt.
Diese Seite stellt die wichtigsten Zeichensätze vor, auf die man stoßen kann — ASCII, ANSI, ISO-8859-1 und Unicode/UTF-8 — und zeigt, wie die Kodierung sowohl in modernem als auch in älterem HTML deklariert wird.
Was schiefgeht, wenn die Kodierung fehlt oder nicht übereinstimmt
Wenn eine Seite ihre Kodierung nicht deklariert oder eine Kodierung angibt, die nicht mit der tatsächlichen Speicherung der Datei übereinstimmt, rät der Browser — und liegt dabei oft falsch. Das häufigste Symptom ist Mojibake: verstümmelter Text, bei dem Buchstaben mit Akzenten, geschweifte Anführungszeichen oder Emoji zu Zeichenketten wie é oder ’ werden.
Abgesehen davon, dass es fehlerhaft aussieht, kann ein nicht deklarierter oder nicht übereinstimmender Zeichensatz ein Sicherheitsproblem darstellen: Einige Angriffe beruhen darauf, dass der Browser Bytes unter einer anderen Kodierung interpretiert, als der Autor beabsichtigt hat (zum Beispiel UTF-7-basiertes Cross-Site-Scripting). Die Angabe einer einzigen, expliziten Kodierung im Voraus beseitigt diese Mehrdeutigkeit. Die sichere, moderne Wahl ist, Inhalte stets als UTF-8 auszuliefern und dies klar mit <meta charset="UTF-8"> anzugeben.
ASCII
ASCII war der erste Standard für Zeichenkodierung, der auch als Zeichensatz bezeichnet wird. Es ist eine Abkürzung für American Standard Code for Information Interchange.
Für jedes speicherbare Zeichen definierte ASCII eine eindeutige Nummer, um Groß- und Kleinbuchstaben (a–z, A–Z), die Ziffern 0–9 und eine Handvoll Sonderzeichen zu unterstützen. ASCII basiert auf dem englischen Alphabet und kodiert 128 Zeichen in eine 7-Bit-Ganzzahl in Binärdarstellung. Der Großbuchstabe A hat beispielsweise den Code 65 (binär 01000001), a den Code 97 und die Ziffer 0 den Code 48. Das funktioniert, weil alle Computerinformationen letztendlich als binäre Einsen und Nullen in der Elektronik gespeichert werden.
Nachfolgend ist eine ASCII-Tabelle zu sehen, die jedem Zeichen seinen dezimalen, hexadezimalen und binären Code zuordnet.
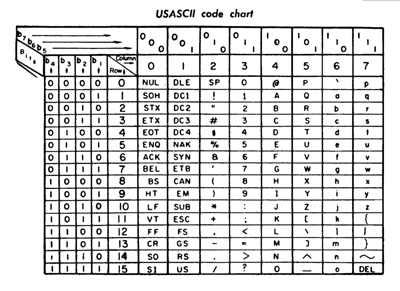
Die größte Einschränkung von ASCII ist, dass es keine nicht-englischen Buchstaben oder Zeichen mit Akzenten enthält. Es wird heute noch verwendet, insbesondere in Großrechnern, und bildet das Fundament, auf dem spätere Kodierungen (einschließlich UTF-8) aufbauen.
Hier klicken, um mehr über ASCII zu erfahren.
ANSI
ANSI, auch Windows-1252 genannt, war der Standard-Zeichensatz für Windows bis Windows 95. Es ist eine Erweiterung von ASCII, die internationale Zeichen hinzufügt. Es unterstützte 256 Zeichen mit einem vollständigen Byte (8 Bit).
ANSI wurde von allen Browsern unterstützt, da es als Standard-Zeichensatz von Windows angekündigt wurde.
ISO-8859-1
ISO-8859-1 wurde zum Standard-Zeichensatz in HTML 2.0, da die meisten Länder andere Zeichen als ASCII verwenden. Es ist wie ANSI ebenfalls eine Erweiterung von ASCII und fügt internationale Zeichen hinzu. ISO-8859-1 verwendet ebenfalls ein vollständiges Byte, um doppelt so viele Zeichen wie ASCII darzustellen.
Hier klicken, um mehr über ISO-8859-1 zu erfahren.
Standard-Kodierung in HTML 4
In HTML 4 wurde die Kodierung mit einem http-equiv-<meta>-Tag deklariert. Da ISO-8859-1 der Standard war, würde man ihn folgendermaßen explizit angeben:
<meta http-equiv="Content-Type" content="text/html;charset=ISO-8859-1" />Den Zeichensatz in HTML 4 überschreiben
Wenn eine HTML-4-Seite eine andere Zeichenkodierung als den ISO-8859-1-Standard benötigt — zum Beispiel ISO-8859-8 für Hebräisch — ändert man einfach den charset-Wert im selben <meta>-Tag:
<meta http-equiv="Content-Type" content="text/html;charset=ISO-8859-8" />Die meisten HTML-4-Prozessoren verstanden auch UTF-8, was den Weg ebnete, es zum Standard in HTML5 zu machen.
Die HTML5-Methode
HTML5 ersetzte die ausführliche http-equiv-Form durch ein kurzes, dediziertes Attribut:
<meta charset="UTF-8" />Dieses Tag sollte so früh wie möglich innerhalb des <head>-Elements platziert werden — idealerweise als erstes Kind-Element — damit der Browser die Kodierung liest, bevor er Textinhalte parst.
Unicode UTF-8
UTF-8 ist die Standard- und empfohlene Zeichenkodierung für HTML5.
Da die oben beschriebenen Zeichensätze jeweils auf maximal 256 Zeichen begrenzt sind, entwickelte das Unicode-Konsortium den Unicode-Standard, einen einzigen Katalog, der fast jedem Zeichen, Satzzeichen und Symbol, das weltweit verwendet wird — über Tausende von Sprachen hinweg, plus Emoji und mathematische Symbole — eine eindeutige Nummer (sogenannter Codepunkt) zuweist. UTF-8 ist die gebräuchlichste Methode, diese Codepunkte als Bytes zu kodieren.
Warum UTF-8 der moderne Standard ist
Drei Eigenschaften machen UTF-8 zur natürlichen Wahl für das Web:
- Universelle Abdeckung. Es kann jeden Unicode-Codepunkt darstellen, sodass eine einzelne Seite Englisch, Arabisch, Chinesisch und Emoji ohne Wechsel der Kodierung mischen kann.
- ASCII-kompatibel. Die ersten 128 Codepunkte werden als exakt dieselben einzelnen Bytes wie bei ASCII kodiert. Jede reine ASCII-Datei ist bereits gültiges UTF-8, was bedeutet, dass Jahrzehnte alter Text und Werkzeuge weiterhin funktionieren.
- Variable Breite und Effizienz. Häufige Zeichen belegen nur ein Byte, während weniger häufige nach Bedarf zwei, drei oder vier Bytes verwenden. Dokumente, die größtenteils Englisch enthalten, bleiben kompakt, doch nichts wird ausgelassen.
In HTML gibt das charset-Attribut im <meta>-Tag die Kodierung an:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8" />
<title>UTF-8 example</title>
</head>
<body>
<p>English, Русский, 中文, العربية, 😀</p>
</body>
</html><meta charset="UTF-8"> sollte als erstes Element im <head> stehen (innerhalb der ersten 1024 Bytes des Dokuments). Kommt es zu spät, beginnt der Browser möglicherweise, Text unter der falschen Kodierung zu parsen, bevor er die Deklaration sieht.
Mehrbyte-Zeichen und das BOM
In UTF-8 kann ein einzelnes Zeichen mehrere Bytes umfassen. Das Eurozeichen € (Unicode-Codepunkt U+20AC) wird beispielsweise als drei Bytes E2 82 AC gespeichert, während ein Zeichen wie A nach wie vor nur ein Byte benötigt. Das ist gemeint, wenn von „variabler Breite" die Rede ist.
Man kann auch auf das BOM (Byte Order Mark) stoßen, eine optionale unsichtbare Bytefolge (EF BB BF für UTF-8) am absoluten Anfang einer Datei, die deren Kodierung signalisiert. Ein BOM ist für UTF-8 nicht erforderlich und wird in HTML am besten weggelassen, da ein explizites <meta charset="UTF-8"> die Aufgabe bereits erfüllt und ein unerwartetes BOM gelegentlich Darstellungsprobleme verursachen kann.
Um bestimmte Symbole einzufügen, ohne sich darum kümmern zu müssen, wie der Editor die Datei speichert, können auch benannte oder numerische HTML-Entitäten verwendet werden (zum Beispiel € für €).
Alle HTML5-Prozessoren unterstützen UTF-8. Beachten Sie, dass XML-Prozessoren strikt UTF-8 oder UTF-16 erfordern.